Previously, our services would be as follows.
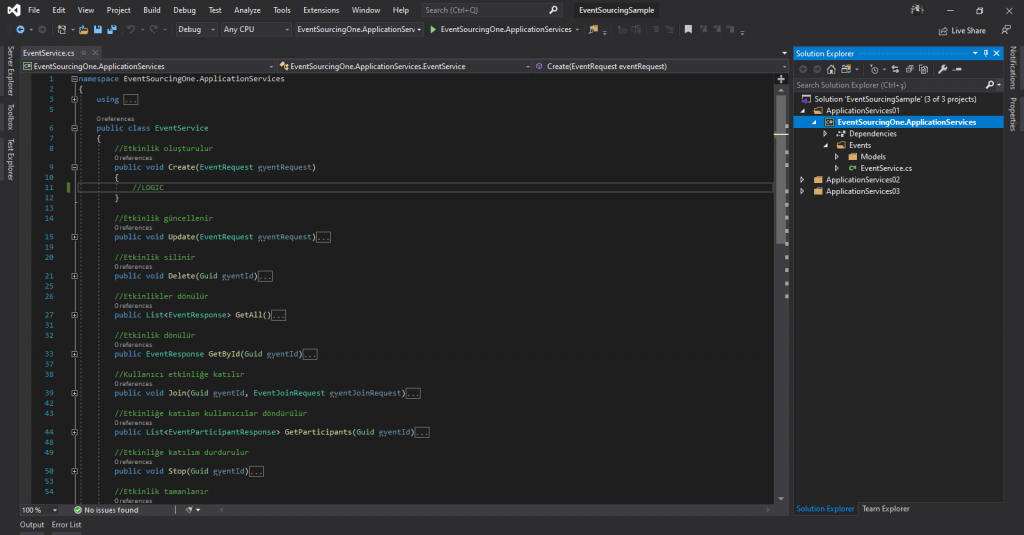
This service consisted of hundreds of lines of code. To get rid of this confusion, we split our services into two parts as "Command" and "Query" with CQRS. We performed our CRUD operations with "Command" services and our query operations with "Query" services. Two separate services appeared as follows.
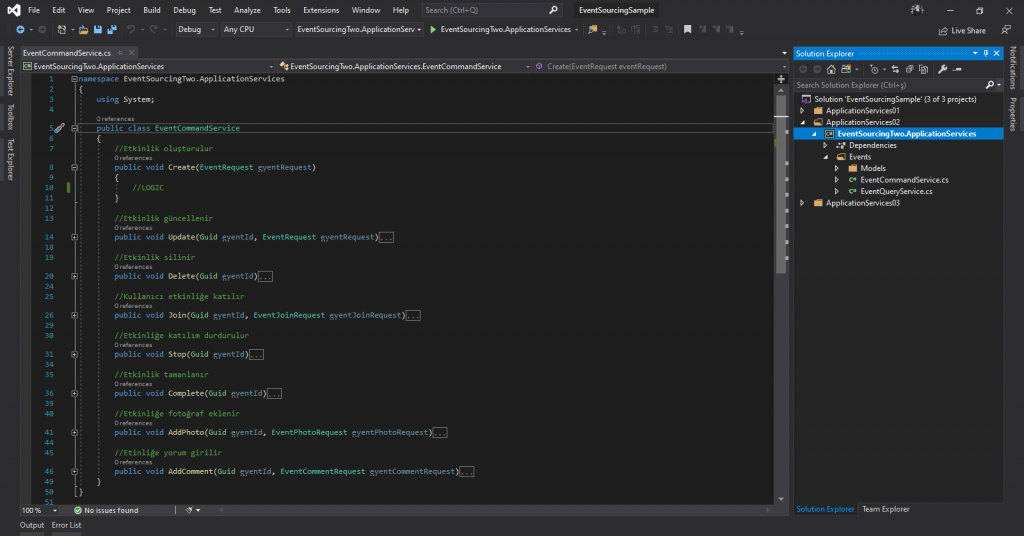
In this way, we achieved a little readability, but god classes were still emerging. "UseCase" s have entered our lives with Mediator. This time we started creating separate handlers for each "UseCase". 13 separate handlers appeared as follows.
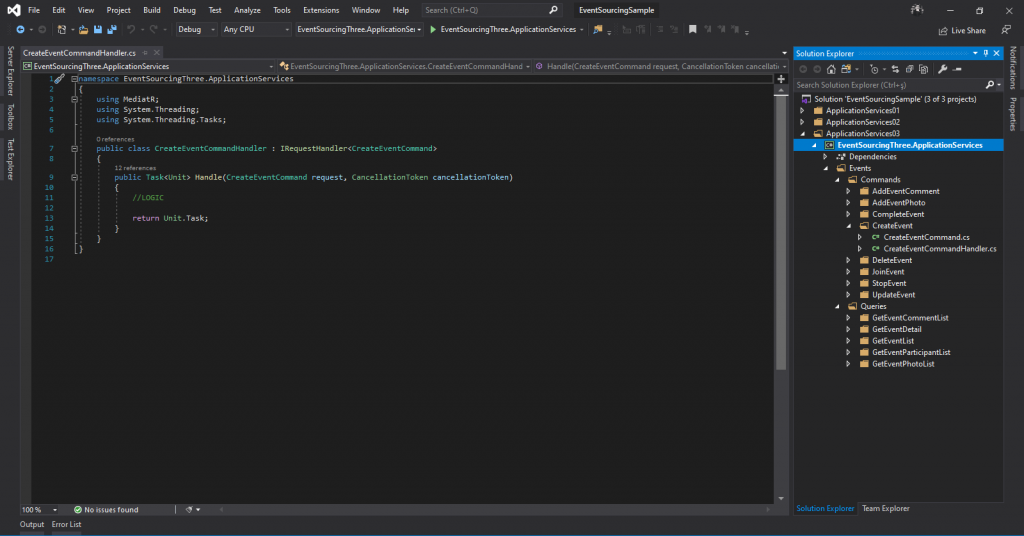
With this approach, each handler just did its own job. The lines of code decreased further, readability increased even more. This gave us easy maintainability.
This time we worked on performance. Each emerging database technology offered different features. Some of them was very good for fast writing and some of them was good for fast reading. Since we have seperated everything… We chose database technologies with good writing speed for “Command” operations and database technologies with good reading speed for “Query” operations. There was a problem. We had to synchronize data in two different database technologies.
At this point, "Messaging" technologies came to our rescue. After writing the data to the database in the command handler, we sent the same data to the queues as a message. We wrote a consumer application that listens to messages in the queue. We transferred the messages that came with the consumers to the database which we had selected for “Query” operations. In this way, we achieved synchronization between two different database technologies.
Then we realized that not everything was CRUD. It wasn't all about adding, updating and deleting data. What were we updating?
Let's consider the Meetup application.
For example, we define an event. This is an insert.
After defining the event, we can update the content of the event. This is an update.
Those who plan to attend the event state that they will go to the event. Is this an update for the event? If it is not update, what is it?
We mark the status of the event as "Stopped" an hour before the event has started.
After the event has been finished, we mark the status of the event as "Completed". So is this an update?
As the owner of the event, we upload photos to the event. Is this also an update?
Participants enter comments on the event. Do you think that it is an Update?
As you can see, everything could not be thought of as Insert, Update and Delete. In fact, everything was an event as the following.
- MeetupRegistered
- MeetupJoined
- MeetupStopped
- MeetupCompleted
- MeetupAddedPhoto
- MeetupAddedComment
If everything was an event, there was no need to keep our data in rows in related tables as we do in the classical method. Then we created a table as in the image below and added each event to this table as a line.
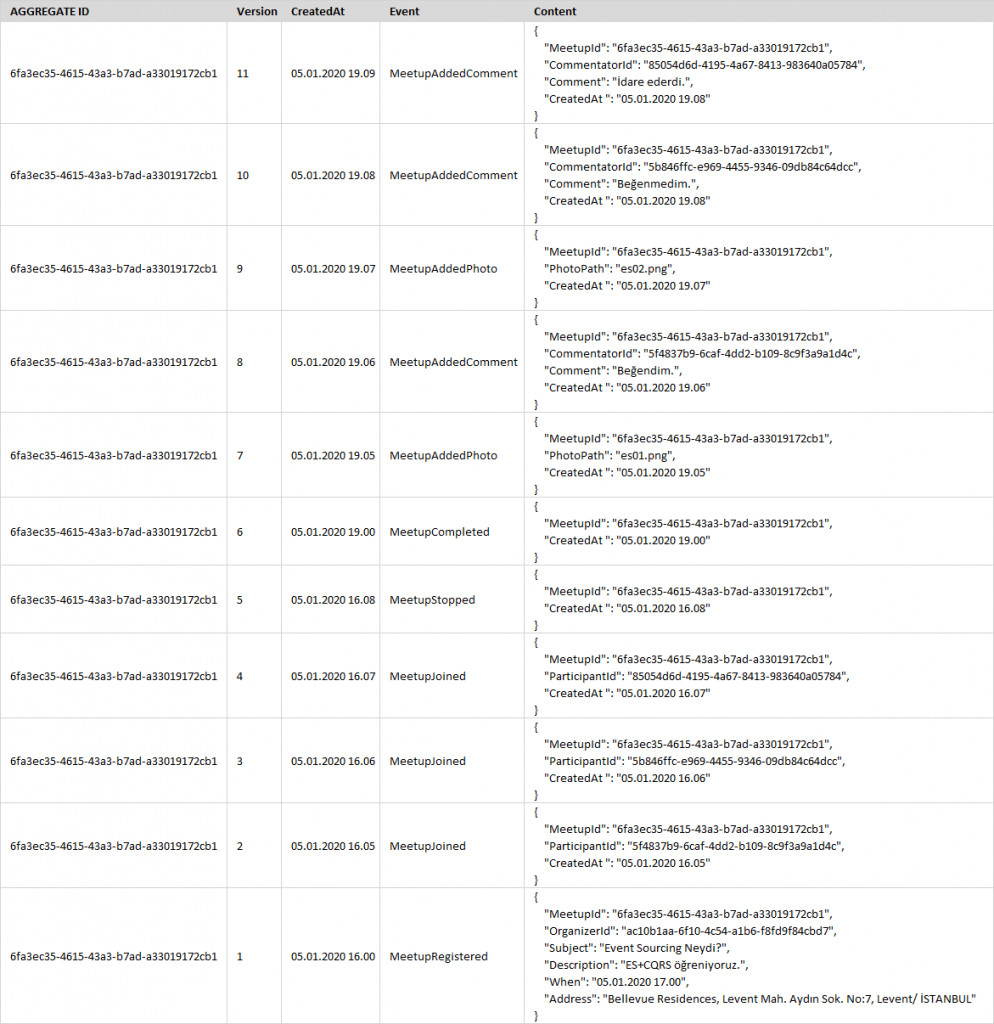
When we look, we see that the event we have defined is just a join of these rows. Each event has its version number. When we join it from bottom to top, the result is as follows.
We said that in the "Command" operations we save our data as an event in a database as above. But since we cannot query these rows, we also need to write these events to the database we choose for "Query". For example when we want to show "incomplete events" in the meetup application, we cannot make an query in the events above.
As I have mentioned in the previous paragraphs, after writing the event information to the database as an event in "Command" operations, we should send this information to a "messaging" queue. We should write a consumer listening to this queue. Through this consumer, we should listen to the "MeetupRegistered" events and write the necessary information and the event information to the "Query" database. In the same way, we should also listen to the "MeetupCompleted" events and delete the event information from the "Query" database.
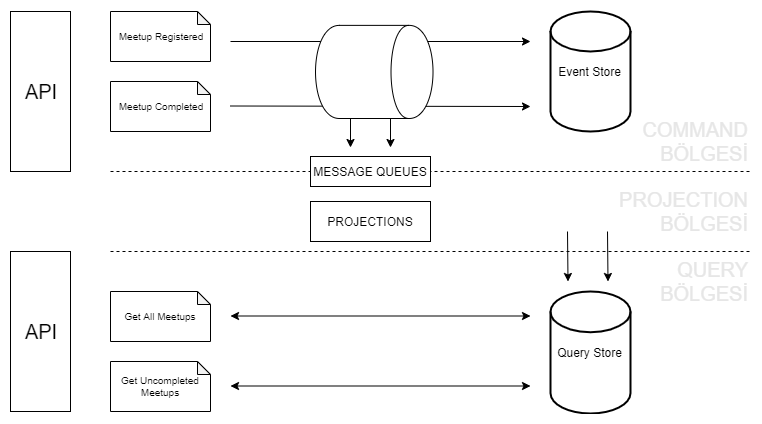
As you can see above, events from the API in the "Command" area are written to the event store. These events are also sent to the queue. In the "Projection" area, the messages in the queue is written by being processed to the query store. Queries are made in the "Query" area, and results are returned from the API.
This is Event Sourcing. It has unique terms like Aggregate, Projection, Snapshot etc. So, what technologies can we choose for "Command", "Messaging" and "Query"?
"MSSQL" can be used for events. "RabbitMQ" can be used for "Messaging". Technologies such as "RavenDB, ElasticSearch, Couchbase" can be used for "Query". But for Event Sourcing, there is a technology called "Event Store" in the .NET world. This technology offers solutions for "Aggregate" and "Projection". In other words, in addition to providing the store where we can record the events, it also provides the "Messaging" and "Projection" services, which are necessary for us to record in “Query” databases.

I have been adding practical informations to my blog rather than theoretical one. So I have prefered to write Tutorial style articles. But this time, I wanted to give first some theoretical informations for Event Sourcing. I intend to come up with a video that we will put the theory into practice soon. In that video, I will develop a sample application without going into definitions too much. For this reason, I wanted to establish the basis for that video with this theoretical article.
Good luck.
Leave a comment
Reply to
Cancel reply